Client-Server Network Scheme
This is the scheme that has been around the longest. It's very simple: there's a central server which provides information or services to it's clients, which are the consumers of it's services. One can't really do much with the server alone, unless one has a client as well.

The problems associated with this scheme are
- scalability: if there's one server, then each client has to go to that server in order to get what they want. So the server's network traffic will be used quite a bit. And if it's the entire world, well, that's a lot of traffic. We can fix this today by distributing the main server across a bunch of servers, which are physically located in different places and have a way to sync between each other. This is a concept known as a specific kind of distributed computing called content distribution network (CDN).

Here, from the clients perspective, they are still connecting to a single server on the network, however, behind the scenes, the server talk to each other to distribute the data, so that a lot of clients can connect at once. This how Google, Amazon, Apple and Microsoft deal with their respective "clouds". - agreeability: if there's only one entry point, then there's one organization that is controlling it. So we need to have all medical institutions agree to use this single entry point.
Hmm, that doesn't sound too easy. OK, maybe we can get the government involved in this. Yeah, what if we somehow manage to make it mandatory for every medical institution to connect to this network? OK, i guess that could work. Well, for a single country. How about the rest of the globe?
And then there are more problems and concerns which actually make this task quite hard, as addressed in Vest and Gamm’s paper titled “Health information exchange: persistent challenges and new strategies”, including:
- healthcare providers’ hesitation to share what they perceive to be proprietary data
- patient concerns about security and privacy
- lack of strong political will from regulators
- historically costly technological solutions, whose costs often fall to healthcare providers but whose benefits often accrue to patients, payers (e.g. insurance companies), and the healthcare system as a whole
We need to look at another way. And here's another way:
Simple un-encrypted client-server model chart
| NO | data lineage and data integrity: audit trail |
| NO | data security: storage and transmission encryptions |
| NO | data authenticity |
| YES | the ability to lockout users |
| EXPENSIVE | backups and snapshots of the data |
| YES | cloud-based |
| YES | on-premise/hosted |
| SLOW | data restoration in the event of a system wide crash |
| EXPENSIVE | scalability |
| EXPENSIVE | high availability |
| NO | difficult to hack |
| NO | agreeable: open and transparent such that every nation and institution can easily agree to join |
Peer-To-Peer Networks
This is a network topology that is fundamentally different than the client server based model. Here's a table that summarizes the basic differences.
| Client-Server | Peer-To-Peer |
|---|---|
| Server is the only provider of resources, clients are the only consumers of resources. | Each node is both consumer and provider of resources. |
| Server decides who has access to what: it runs different software than the clients and is the most powerful node of the network. | Each node is equipotent. Each node runs exactly the same software. |
| To distribute information, a client has to upload it to the server, who is the only one responsible to distribute information to the clients. Clients don't communicate with each other. | To distribute information, a node only needs to upload it to the network only once. Then the rest of the nodes distribute it amongst each other. |
| Performance decreases as clients increase, because the server gets overwhelmed. | Performance increases as nodes increase, because the number of resource providers increase as well (each node is a resource provider, see above). |
| Hackers need to take one server down to kill the entire network. | Hackers need to take over (in most cases) at least 51% of the network nodes in order to compromise data on the network. |
In a p2p network (peer-to-peer) there is no central servers. This means that there is no central authority which needs to setup the network and pay for infrastructure costs. Every peer on the network agrees, by joining, to share it's resources. so the network sets its self up. Or, each peer on the network is a contributor for setting up the network.
")
There are plenty of resources on the internet that explain how p2p networks work. You can start with the wikipedia page. If we look at our requirements table, we can see a significant improvement: this technology is really powerful. However, an encrypted p2p network alone will not help us make our dream come true, because it will not address one of the fundamental requirements of counterfeit protection: audit trail and data lineage. In other words, just by slapping our medical records on an encrypted p2p network will still allow anyone to delete anybody else's records. Not good.
Peer-To-Peer network with asymmetric encryption chart
NO | data lineage and data integrity: audit trail |
| YES | data security: storage and transmission encryptions |
| YES | data authenticity |
POSSIBLY | the ability to lockout users |
| YES | backups and snapshots of the data |
| YES | cloud-based |
| YES | on-premise/hosted |
| N/A | data restoration in the event of a system wide crash |
| YES | scalability |
| YES | high availability |
POSSIBLY | difficult to hack |
| YES | agreeable: open and transparent such that every nation and institution can easily agree to join |
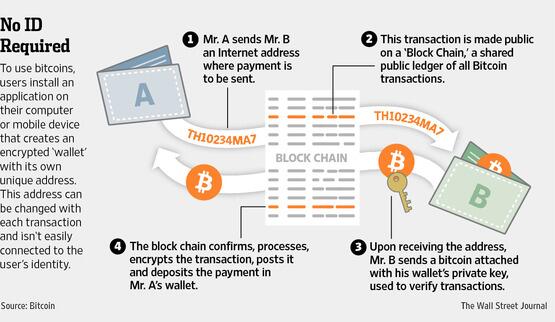{kind=link}
Footnotes