Asymmetric Cryptography
Back in the 80's, we already had invented asymmetric cryptography: it is a kind of encryption scheme which makes use of a pair of keys, as opposed to Public Shared Key cryptography, which makes use of a single key. However, the fact that there were not so many users on the networks and that computers were pretty slow made it impractical to implement. At any rate, theoretically some visionary could have implemented this, and added to the client-server architecture above. By the late 90's we definitely could have had a server-client and encrypted healthcare network.
In public shared key (PSK), two parties that want to communicate with each other in public without having others understand, need to privately exchange a key first. This is what has been done, for example, during the second world war, when spies used to have these code books. The trick here is to make sure each character is encrypted with a different key, and never to repeat the same key. That's why they needed code "books".
Now, one can understand how inconvenient this would be for the internet. Using conventional PSKs, one cannot establish a secure communication, one could not open a website with the secure https channel, without first physically going to the website's headquarters and exchanging a key. Or having the key arrive in a sealed envelope.
With asymmetric encryption, one key is used to encrypt, while the other is used to decrypt. It is not possible to use the same key to do both. So here's how ti goes:
- Alice logs onto the Bank's website.
- Bank replies to Alice with it's public key. Who cares if somebody else intercepts the key. It will only mean that they will be able to encrypt things that only Bank can decrypt.
- Alice generates a random PSK, and encrypts it with Bank's public key, which it just got over the internet.
- Alice sends over the open internet the encrypted PSK. Who cares, cuz only Bank can decrypt the PSK with it's private key.
- Bank decrypts the PSK with it's private key.
- Now Alice and Bank both have a PSK which they can use to communicate securely and keep changing it as necessary.
Pretty smart, huh? Now, why not continue to communicate with the public/private key scheme? Well, cuz it requires a lot more computational power. In other words PSK encryption is simply way more light weight. Using asymmetric encryption would unnecessarily slow down communications.
Now, because of the nature of this dual key mechanism, we can also use it digitally "sign" a file. See, Alice can sign a document using her private key and save it on the internet somewhere, or send it to Bank over regular email. At a later time, Bank can verify Alice's signature, by using her public key, which is openly available on some kind of identity validating network, like a BMV or city hall or passport office. Some office that already has infrastructure to authenticate someone identity. They are the ones that can store public keys. Say Alice wants to publish her public key on the BMV's database of public keys. Next time her driver's license expires, she could, at her home, or with her mobile device, generate a public/private key pair, and keep the private key with her. Then at the BMV, when they verify her identity, she can give them her public key and show them she has the corresponding private key.
OK, so if we add asymmetric encryption to the client-server schema above, we will have achieved:
- identity verification through digital signatures
- theft protection through encryption
However, we will still be left with data integrity. The above methods will make it extremely hard to counterfeit medical records, (if we make sure they are signed and/or encrypted) however they don't alone prevent an ill-intentioned individual from deleting records. In addition, backups, restores and scalability remain still a huge expensive issue. Not to mention agreeability.


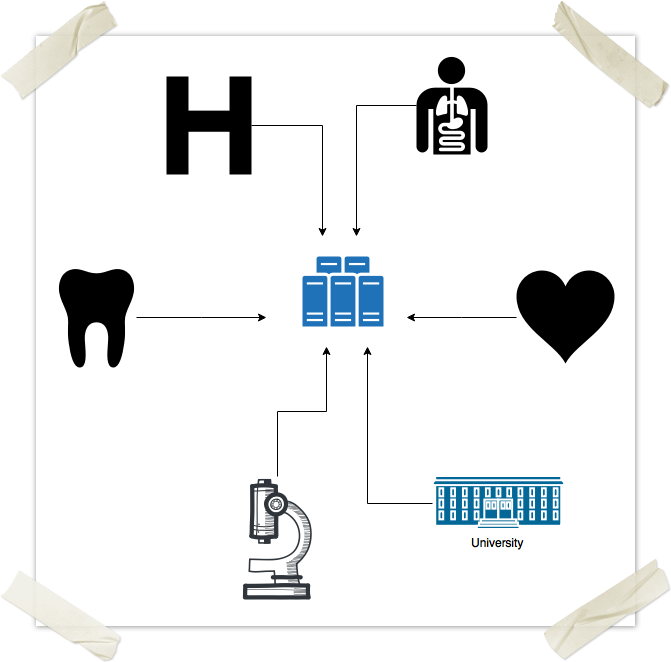
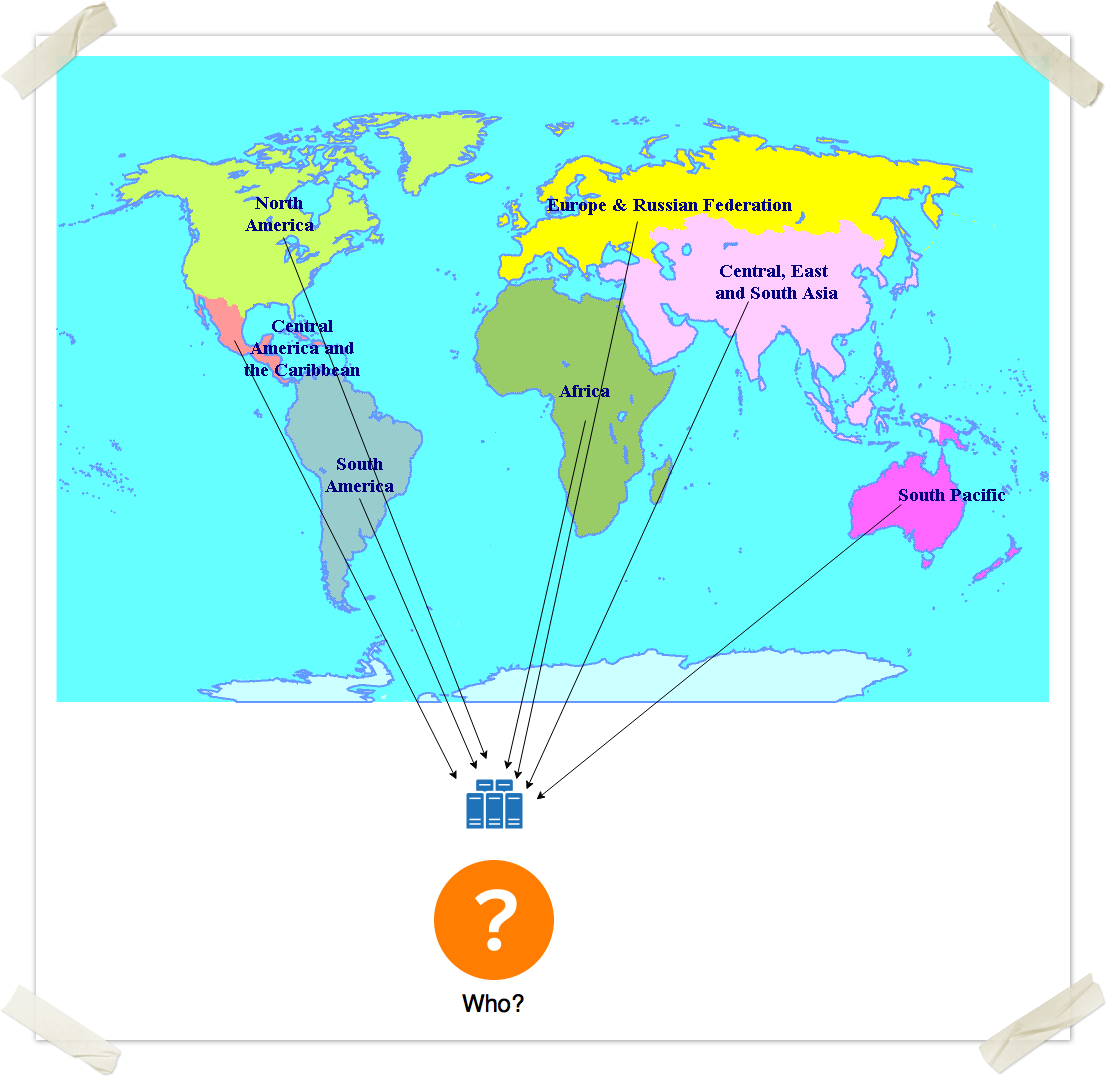
")
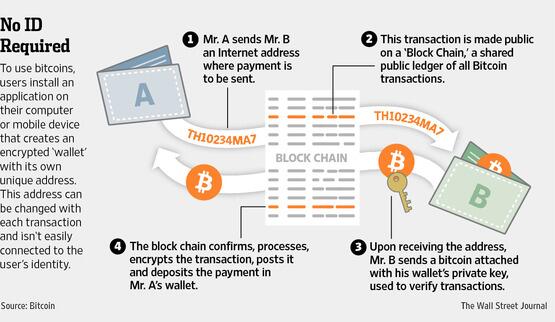{kind=link}